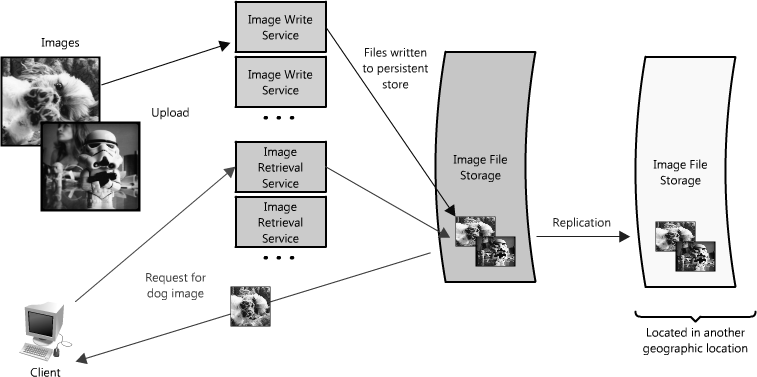
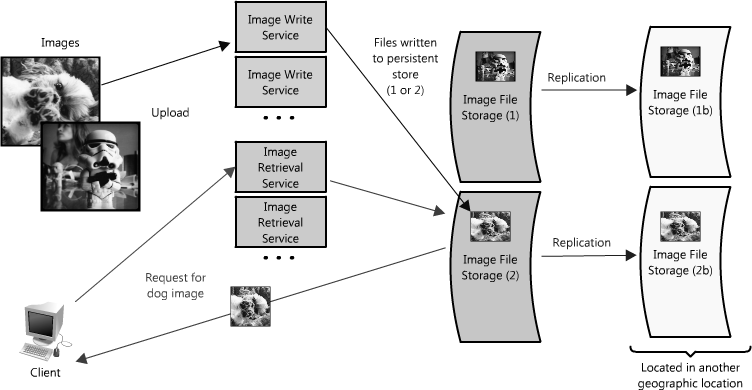
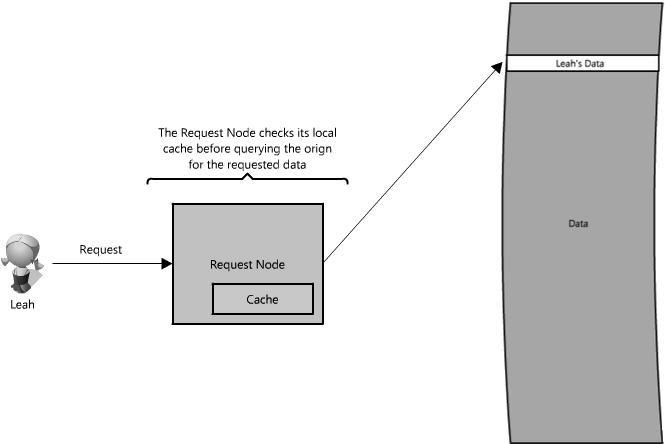
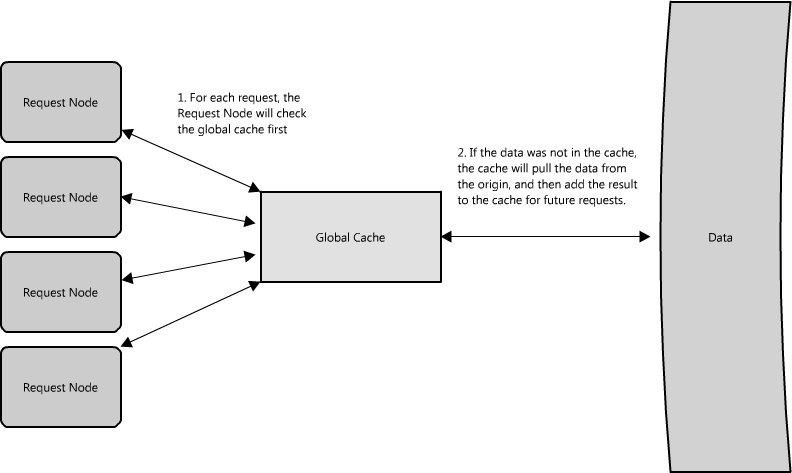
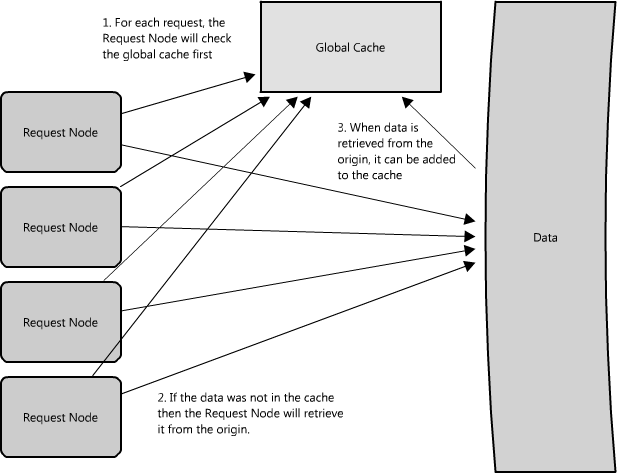
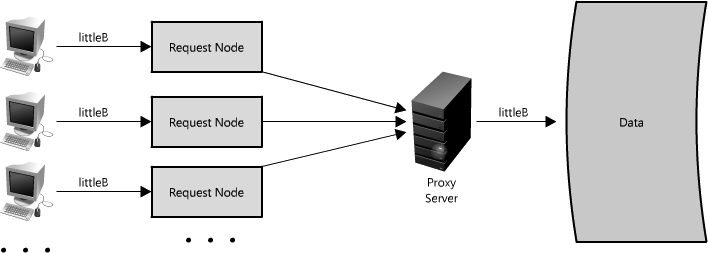
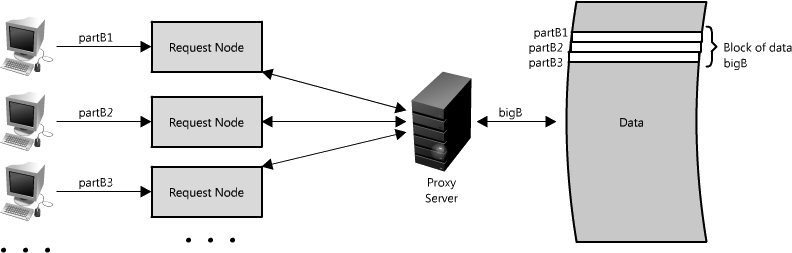
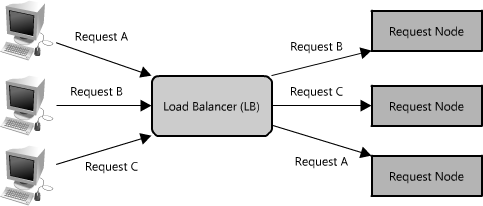
另一个使用代理的方式不只是合并相同数据的请求,同时也可以用来合并靠近存储源(一般是磁盘)的数据请求。采用这种策略可以让请求最大化使用本地数据,这样可以减少请求的数据延迟。比如,一群节点请求B部分信息:partB1,partB2等,我们可以设置代理来识别各个请求的空间区域,然后把它们合并为一个请求并返回一个bigB,大大减少了读取的数据来源(查看图Figure 1.15)。当你随机访问上TB数据时这个请求时间上的差异就非常明显了!代理在高负载情况下,或者限制使用缓存时特别有用,因为它基本上可以批量的把多个请求合并为一个。 Figure 1.15: Using a proxy to collapse requests for data that is spatially close together
值得注意的是,代理和缓存可以放到一起使用,但通常最好把缓存放到代理的前面,放到前面的原因和在参加者众多的马拉松比赛中最好让跑得较快的选手在队首起跑一样。因为缓存从内存中提取数据,速度飞快,它并不介意存在对同一结果的多个请求。但是如果缓存位于代理服务器的另一边,那么在每个请求到达cache之前都会增加一段额外的时延,这就会影响性能。 如果你正想在系统中添加代理,那你可以考虑的选项有很多;Squid和Varnish都经过了实践检验,广泛用于很多实际的web站点中。这些代理解决方案针对大部分client-server通信提供了大量的优化措施。将二者之中的某一个安装为web服务器层的反向代理(reverse proxy,下面负载均衡器一节中解释)可以大大提高web服务器的性能,减少处理来自客户端的请求所需的工作量。
索引
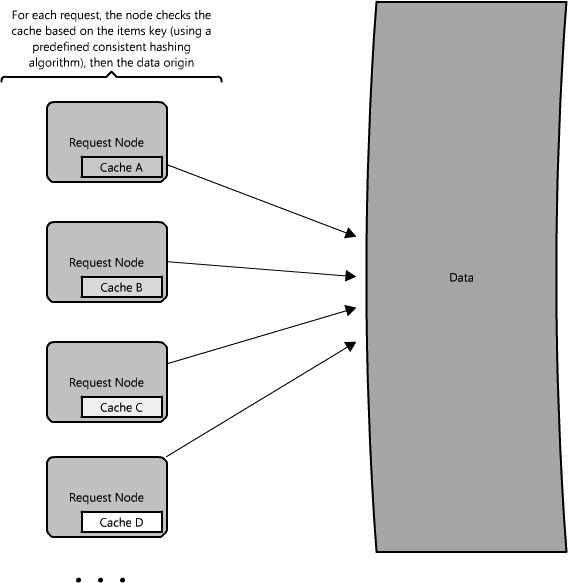
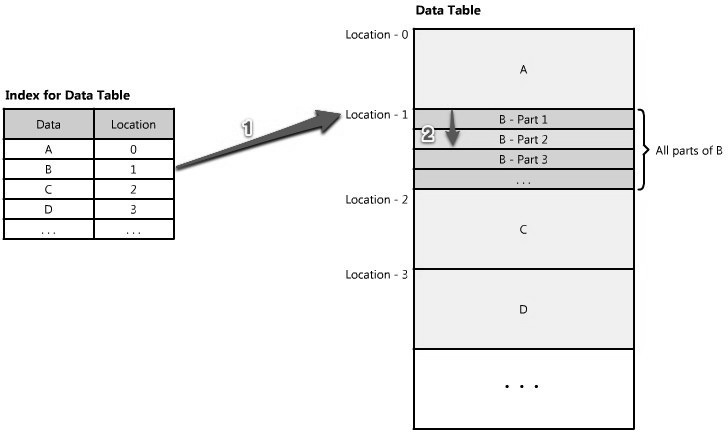
使用索引快速访问数据是个优化数据访问性能公认的策略;可能我们大多数人都是从数据库了解到的索引。索引用增长的存储空间占用和更慢的写(因为你必须写和更新索引)来换取更快的读取。 你可以把这个概念应用到大数据集中就像应用在传统的关系数据存储。索引要关注的技巧是你必须仔细考虑用户会怎样访问你的数据。如果数据集有很多TBs,但是每个数据包(payload)很小(可能只有1KB),这时就必须用索引来优化数据访问。在这么大的数据集找到小的数据包是个很有挑战性的工作因为你不可能在合理的时间內遍历所有数据。甚至,更有可能的是这么大的数据集分布在几个(甚至很多个)物理设备上-这意味着你要用些方法找到期望数据的正确物理位置。索引是最适合的方法做这种事情。 Figure 1.16: Indexes
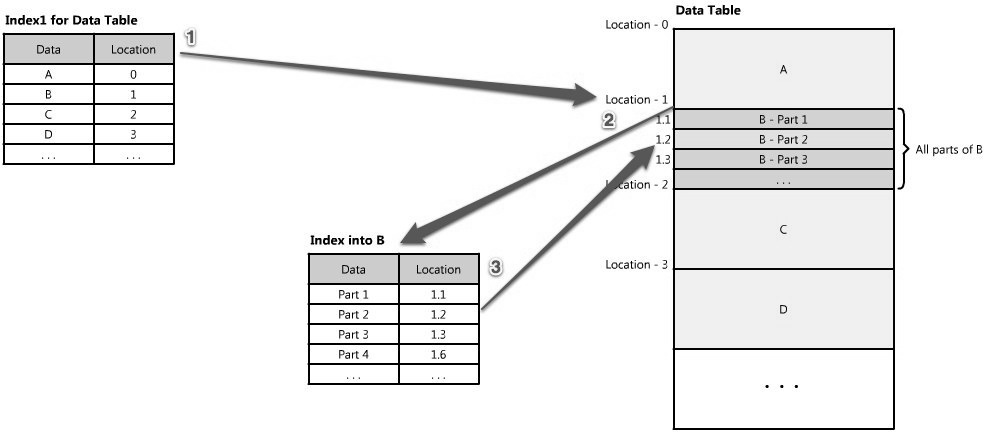
索引可以作为内容的一个表格-表格的每一项指明你的数据存储的位置。例如,如果你正在查找B的第二部分数据-你如何知道去哪里找?如果你有个根据数据类型(数据A,B,C)排序的索引,索引会告诉你数据B的起点位置。然后你就可以跳转(seek)到那个位置,读取你想要的数据B的第二部分。 (See Figure 1.16.) 这些索引常常存储在内存中,或者存储在对于客户端请求来说非常快速的本地位置(somewhere very local)。Berkeley DBs (BDBs)和树状数据结构常常按顺序存储数据,非常理想用来存储索引。 常常索引有很多层,当作数据地图,把你从一个地方指向另外一个地方,一直到你的得到你想要的那块数据。(See Figure 1.17.) Figure 1.17: Many layers of indexes
索引也可以用来创建同样数据的多个不同视图(views)。对于大数据集来说,这是个很棒的方法来定义不同的过滤器(filter)和类别(sort),而不用创建多个额外的数据拷贝。 例如,想象一下,图片存储系统开始实际上存储的是书的每一页的图像,而且服务允许客户查询这些图片中的文字,搜索每个主题的所有书的内容,就像搜索引擎允许你搜索HTML内容一样。在这种情况下,所有的书的图片占用了很多很多服务器存储,查找其中的一页给用户显示有点难度。首先,用来查询任意词或者词数组(tuples)的倒排索引(inverse indexes)需要很容易的访问到;然后,导航到那本书的确切页面和位置并获取准确的图片作为返回结果,也有点挑战性。所以,这种境况下,倒排索引应该映射到每个位置(例如书B),然后B要包含一个索引每个部分所有单词,位置和出现次数的索引。 可以表示上图Index1的一个倒排索引,可能看起来像下面的样子-每个词或者词数组对应一个包含他们的书。 | Word(s) | Book(s) | | being awesome | Book B, Book C, Book D | | always | Book C, Book F | | believe | Book B |
这个中间索引可能看起来像上面的样子,但是可能只包含词,位置和书B的信息。这种嵌套的索引架构要使每个子索引占用足够小的空间,以防所有的这些信息必须保存在一个大的倒排索引中。
这是大型系统的关键点,因为即使压缩,这些索引也太大,太昂贵(expensive)而难以存储。在这个系统,如果我们假设我们世界上的很多书-100,000,000 (see Inside Google Books blog post)-每个书只有10页(只是为了下面好计算),每页有250个词,那就是2500亿(250 billion)个词。如果我们假设每个词有5个字符,每个字符占用8位(或者1个字节,即使某些字符要用2个字节),所以每个词占用5个字节,那么每个词即使只包含一次,这个索引也要占用超过1000GB存储空间。那么,你可以明白创建包含很多其他信息-词组,数据位置和出现次数-的索引,存储空间增长多快了吧。 创建这些中间索引和用更小分段表示数据,使的大数据问题可以得到解决。数据可以分散到多个服务器,访问仍然很快。索引是信息检索(information retrieval)的奠基石,是现代搜索引擎的基础。当然,我们这段只是浅显的介绍,还有其他很多深入研究没有涉及-例如如何使索引更快,更小,包含更多信息(例如关联(relevancy)),和无缝的更新(在竞争条件下(race conditions),有一些管理性难题;在海量添加或者修改数据的更新中,尤其还涉及到关联(relevancy)和得分(scoring),也有一些难题)。 快速简便的查找到数据是很重要的;索引是可以达到这个目的有效简单工具。
负载均衡器
最后还要讲讲所有分布式系统中另一个比较关键的部分,负载均衡器。负载均衡器是各种体系结构中一个不可或缺的部分,因为它们担负着将负载在处理服务请求的一组节点中进行分配的任务。这样就可以让系统中的多个节点透明地服务于同一个功能(参见图1.18)。它的主要目的就是要处理大量并发的连接并将这些连接分配给某个请求处理节点,从而可使系统具有伸缩性,仅仅通过添加新节点便能处理更多的请求。 图1.18: 负载均衡器
用于处理这些请求的算法有很多种,包括随机选取节点、循环式选取,甚至可以按照内存或CPU的利用率等等这样特定的条件进行节点选取。负载均衡器可以用软件或硬件设备来实现。近来得到广泛应用的一个开源的软件负载均衡器叫做 HAProxy)。
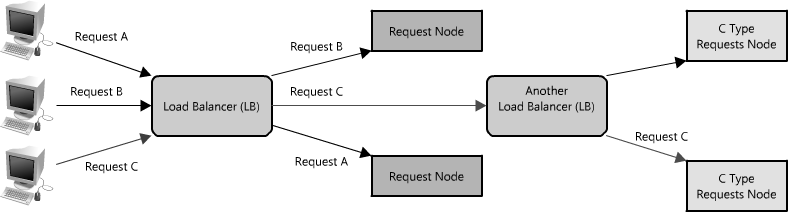
在分布式系统中,负载均衡器往往处于系统的最前端,这样所有发来的请求才能进行相应的分发。在一些比较复杂的分布式系统中,将一个请求分发给多个负载均衡器也是常事,如图1.19所示。 图1.19: 多重负载均衡器
和代理类似,有些负载均衡器还可以基于请求的类型对不同的请求进行不同的处理(技术上讲,这样的叫做反向代理)。
负载均衡器面临的一个难题是怎么管理同用户的session相关的数据。在电子商务网站中,如果你只有一个客户端,那么很容易就可以把用户放入购物车里的东西保存起来,等他下次访问访问时购物车里仍能看到那些东西(这很重要,因为当用户回来发现仍然呆在购物车里的产品时很有可能就会买它)。然而,如果在一个session中将用户分发到了某个节点,但该用户下次访问时却分发到了另外一个节点,这里就有可能产生不一致性,因为新的节点可能就没有保留下用户购物车里的东西。(要是你把6盒子子农夫山泉放到购物车里了,可下次回来一看购物车空了,难道你不会发火吗?) 解决该问题的一个方法是可以使session具有保持性,让同一用户总是分发到同一个节点之上,但这样一来就很难利用类似failover这样的可靠性措施了。如果这样的话,用户的购物车里的东西不会丢,但如果用户保持的那个节点失效,就会出现一种特殊的情况,购物车里的东西不会丢这个假设再也不成立了(虽然但愿不要把这个假设写到程序里)。当然,这个问题还可以用本章中讲到的其它策略和工具来解决,比如服务以及许多并没有讲到的方法(象服务器缓存、cookie以及URL重写)。
如果系统中只有不太多的节点,循环式(round robin)DNS系统这样的方案也许更有意义,因为负载均衡器可能比较贵,而且还额外增加了一层没必要的复杂性。当然,在比较大的系统中会有各种各样的调度以及负载均衡算法,简单点的有随机选取或循环式选取,复杂点的可以考虑上利用率以及处理能力这些因素。所有这些算法都是对浏览和请求进行分发,并能提供很有用的可靠性工具,比如自动failover或者自动提出失效节点(比如节点失去响应)。然而,这些高级特性会让问题诊断难以进行。例如,当系统载荷较大时,负载均衡器可能会移除慢速或者超时的节点(由于节点要处理大量请求),但对其它节点而言,这么做实际上是加剧了情况的恶化程度。在这时进行大量的监测非常重要,因为系统总体流量和吞吐率可能看上去是在下降(因为节点处理的请求变少了),但个别节点却越来越忙得不可开交。 负载均衡器是一种能让你扩展系统能力的简单易行的方式,和本文中所讲的其它技术一样,它在分布式系统架构中起着基础性的作用。负载均衡器还要提供一个比较关键的功能,它必需能够探测出节点的运行状况,比如,如果一个节点失去响应或处于过载状态,负载均衡器可以将其总处理请求的节点池中移除出去,还接着使用系统中冗余的其它不同节点。
| 










 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜